![]()
Archiving and transforming community documentation notes into a memex

Organizational challenges
- meetings are at a weekly or bi-weekly cadence
- we often only pay attention to previous meetup notes
- discord / zoom calls all sorta look / feel the same
- we are bombarded with URLs that they become easy to forget
- every URL / tab is sorta silo'd from each other in terms of context switching
- It'd be nice if we can see multiple pages in one place (like on an infinite canvas)
Questions
- How can we visualize our activities and bigger picture better?
- How can new people see a high level overview of past 5 meetups?
- How can we streamline the process for organizations to have a longer memory?
Requirements:
- https://github.com/omigroup/recordings (private data source of mp3 files)
- https://github.com/Vaibhavs10/insanely-fast-whisper
- https://ollama.com/library/dolphin-mistral
Convert to mp3 using FFmpeg or something
ffmpeg -i file.mp4 out.mp3
Transcribe meeting recordings with insanely fast whisper
for i in *.mp3; do insanely-fast-whisper --file-name "$i" --transcript-path "$(basename "$i" .mp3)".json;done
Get the text from each transcript
cat transcript.json | jq '.text' > transcript.txt
Download dolphin-mistral
ollama run dolphin-mistral
Create a modelfile
FROM dolphin-mistral
PARAMETER temperature 0.1
PARAMETER num_ctx 32000
SYSTEM """
You are an autoregressive language model that has been fine-tuned with instruction-tuning and RLHF.
You carefully provide accurate, factual, thoughtful, nuanced responses, and are brilliant at reasoning.
You task is summarizing transcripts.
You summarize podcasts into bullet points, aiming for 10 or fewer depending on the length of the podcast.
The total length of the summary should be less than 300 words.
It is from a meeting between one or more people.
Please break the transcript into sections, and give a name to each section. Within each section of the outline write a 1-2 sentence summary followed by bullet points.
The first section is a 1 paragraph overall summary followed by key points from the transcript.
The second section are action items discussed.
The third section is a bullet point list outline based on the timeline of topics discussed.
The final section is simply notes, which are freeform bullet point and succinct notes based on non obvious information from the meeting.
Only output the summary and bullet points per section which can include questions asked, any interesting quotes, and any action items that were discussed. Do not repeat the prompt back, or say anything extra.
Do not include any preamble, introduction or postscript about what you are doing. Assume I know.
The input prompt is text containing the transcript of the podcast.
The output is markdown containing a title, high level short summary, and then each sections.
"""
Save the modelfile
ollama create dolphin-summary -f ./modelfile
List models (just do double check)
ollama list
Summarize an individual transcript
ollama run dolphin-summary "I have a transcript from one of the Open Metaverse Interoperability (OMI) group meetings. Can you summarize it? Here is the transcript: $(cat file.txt)"
Summarize all of the transcripts in omigroup recordings (optional)
#!/bin/bash
prompt="I have a transcript from one of the Open Metaverse Interoperability (OMI) group meetings. Can you summarize it? Here is the transcript:"
for file in backlog-refinement/* champions-meeting/* gltf-extensions/* weekly-meeting/*; do
output_dir="output/$(dirname "$file")"
mkdir -p "$output_dir"
ollama run dolphin-summary "$prompt $(cat "$file")" > "$output_dir/notes_$(basename "$file" | sed 's/\.[^.]*$//').txt"
done| OMI Group | OMI glTF Extensions | MSF Delegates |
|---|---|---|
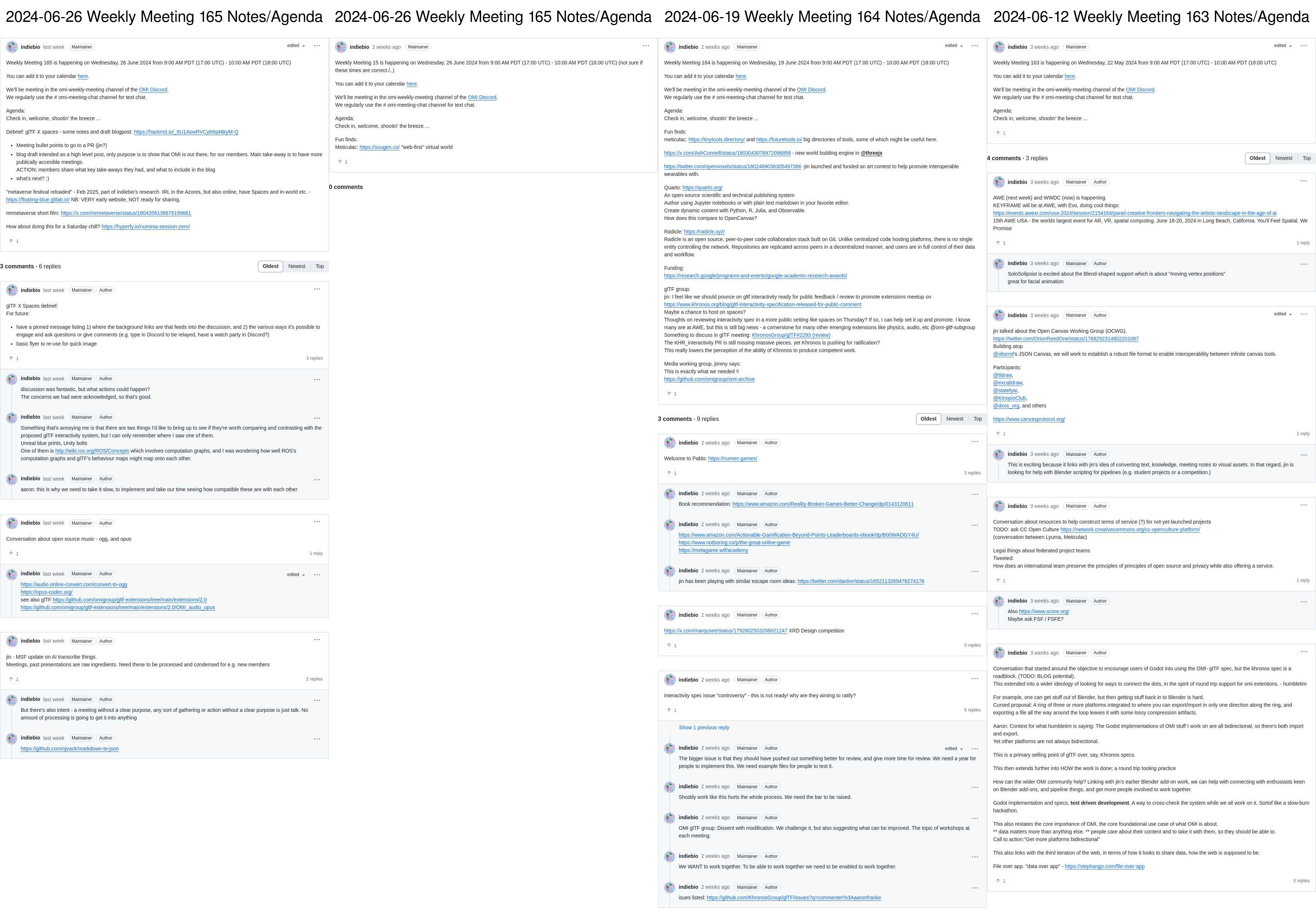 |
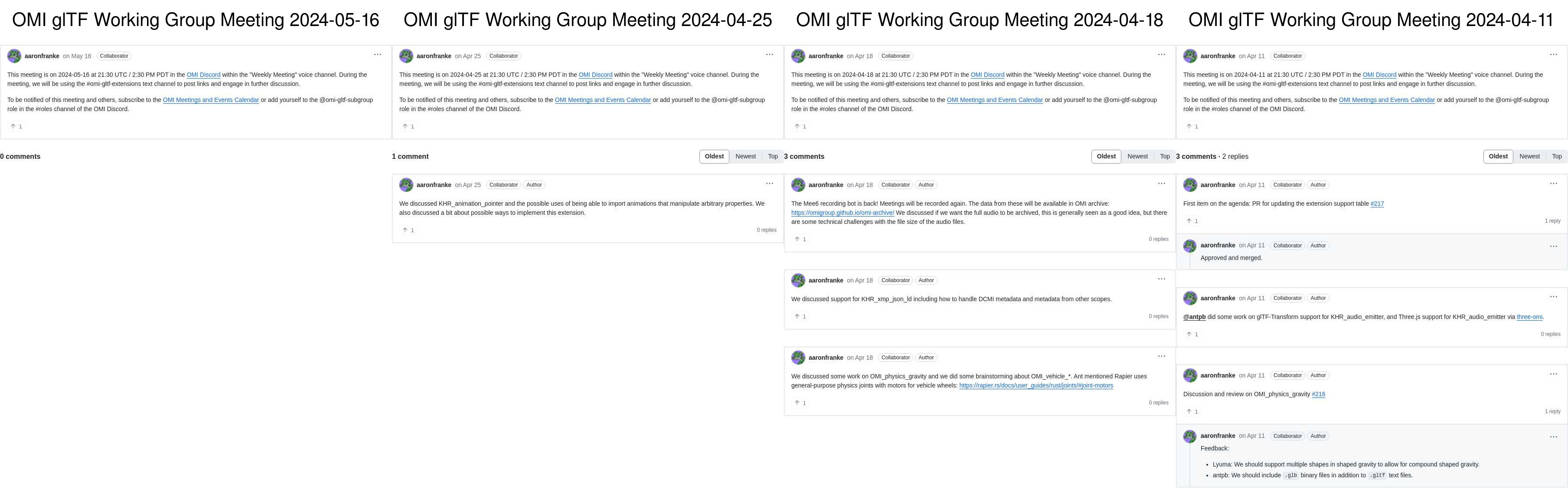 |
 |
| KHR Audio | OMI physics shape | OMI link | OMI Pesonality |
|---|---|---|---|
 |
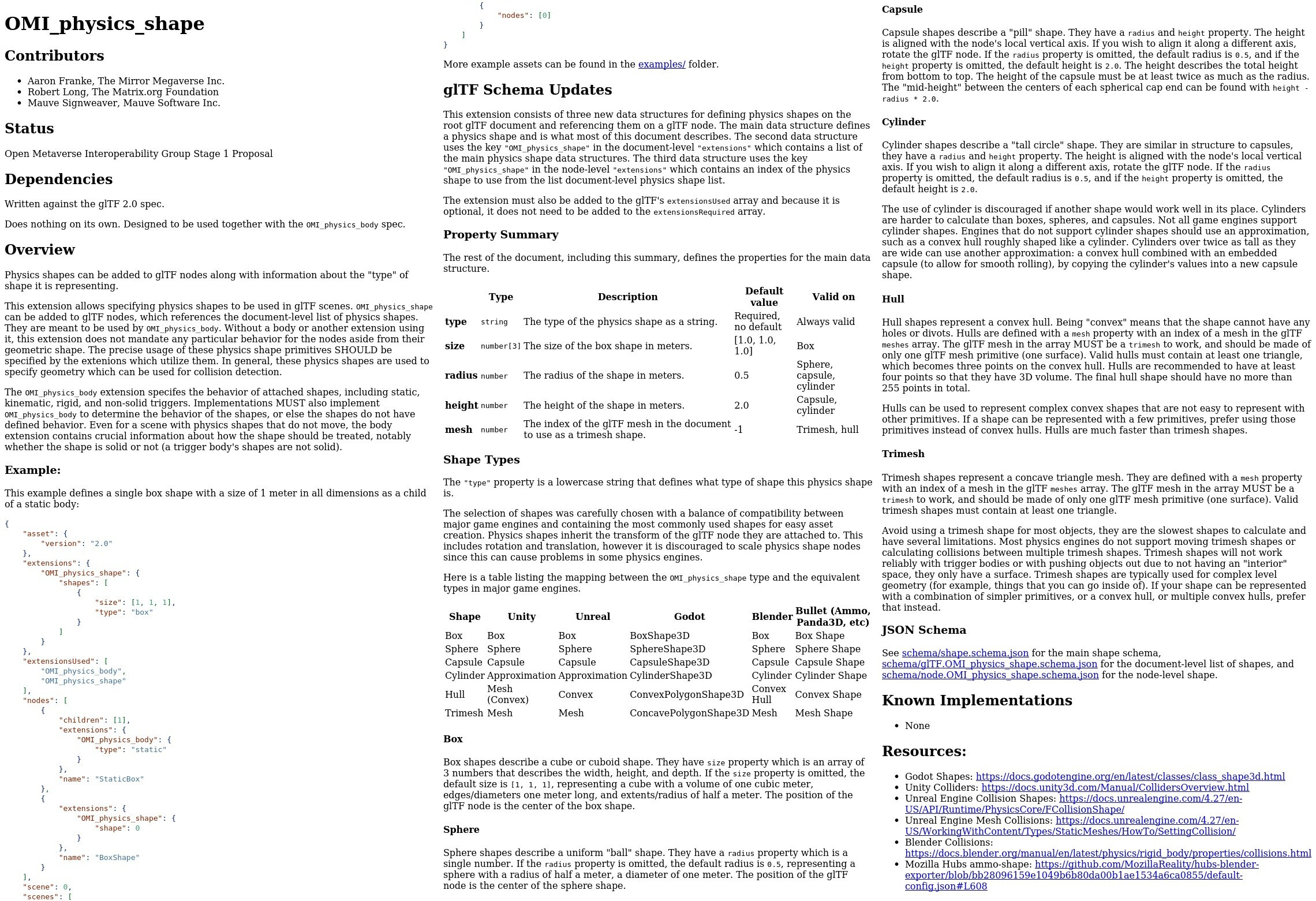 |
 |
 |
| OMI physics body | OMI physics joint | OMI seat | OMI spawn point |
|---|---|---|---|
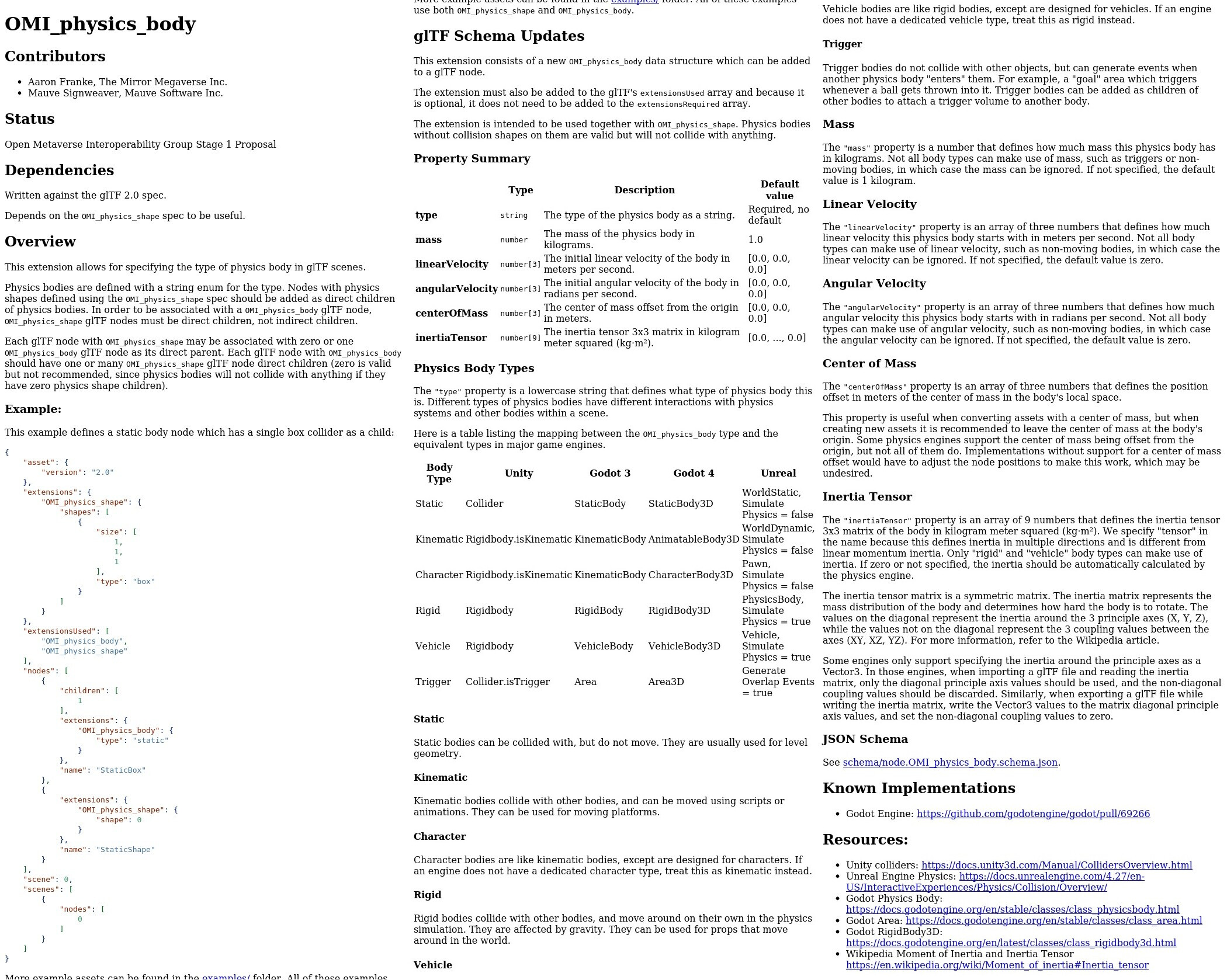 |
 |
 |
 |
PDFs over 100 MB are automatically added to .gitignore (Uploaded to Discord though)